Map and Reduce相关重点概念
MapReduce
MapReduce works by breaking the processing into two phases: the map phase and thereduce phase.
MapReduce把程序分成两个阶段:一个map阶段和一个reduce阶段.
The output from the map function is processed by the MapReduce framework beforebeing sent to the reduce function.
This processing sorts and groups the key-value pairsby key.
经过map之后的结果键值对,MapReduce框架会在reduce之前进行排序和分组.
数据流
任务拆分
Hadoop divides the input to a MapReduce job into fixed-size pieces called input splits,or just splits. Hadoop creates one map task for each split, which runs the user-definedmap function for each record in the split.
Hadoop将输入输入的任务拆分成固定大小的片段,并为每一个片段执行map函数.
任务拆分是为了在多台机器上面并行处理,任务如果拆分的足够小,那么更容易进行负载均衡.
但是另一方面,如果分块拆分的太小了,那么花在分块调度上面的时间可能会超过执行任务的时间.
对于大多数任务,分块的大小为128M,这也是HDFS默认的分块大小.
Map
Map tasks write their output to the local disk, not to HDFS.
Map会将输出存在本地,而不是HDFS.
因为Map产生的结果是中间结果,job完成后这些中间结果是可以丢弃的.
Reduce
Map的输出结果在传递给Reduce之前会在本地进行排序,然后通过网络发送的要进行Reduce的节点上合并数据,再将合并后的数据传入用户定义的Reduce.
Reduce的结果为了保持可靠性,输出结果会存到HDFS中.
shuffle
在Map和Reduce之间的操作.
整个数据流示意图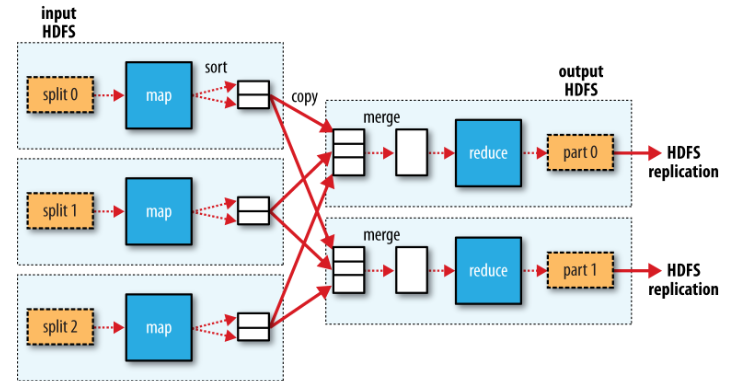
Conbiner Fuctions
解决了什么问题
Mapreduce作业的会被集群之间的带宽限制性能,Conbiner被用来优化map和reduce作业之间的数据交换
hadoop允许用户在map和reduce作业之间自定义conbiner function,因为这是一个优化性能的操作,
hadoop并能保证会在map作业输出时候执行几次.
用处
比如求最大值的时候,可以在各节点计算出最大值之后,在reduce作业中计算各节点最大值中的最大值.

