HDFS数据流
读取数据
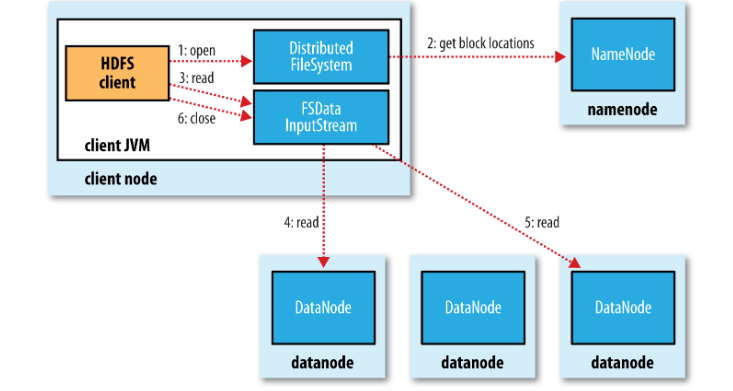
读取数据的过程
- 客户端调用FileSystem对象的open()方法,此对象是 DistributedFileSystem的一个示例.
- DistributedFileSystem通过RPC到namenode获取文件第一个block的地址.并且对于每一个bkock,namenode都会返回具有该block”最近”的地址.
- DistributedFileSystem返回一个FSDataInputStream对象,client通过调用此对象的read方法从指定地址的datanode获取第一个block.当第一个block获取后,将会关闭连接并从最近的datanode获取下一个block.这些对客户端来说都是透明的.
Hadoop如何选择’最近’的block
通过正确配置网络拓扑结构,Hadoop会依照以下优先级选取block地址:
- 同一节点(本机)
- 同一机架
- 同一数据中心
- 不同数据中心
写入数据
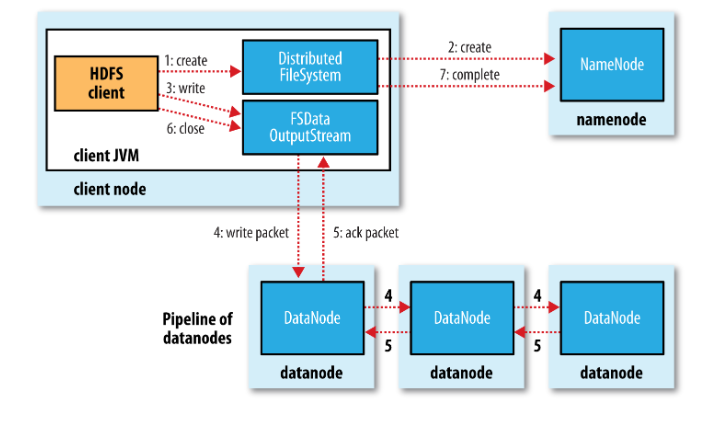
写入数据的过程
- 客户端调用DFS对象的create()方法向namenode发送一个写请求,namenode在执行完一些检查,保证文件不存在并且客户端有权限创建文件之后返回一个DFSOutputStream对象.
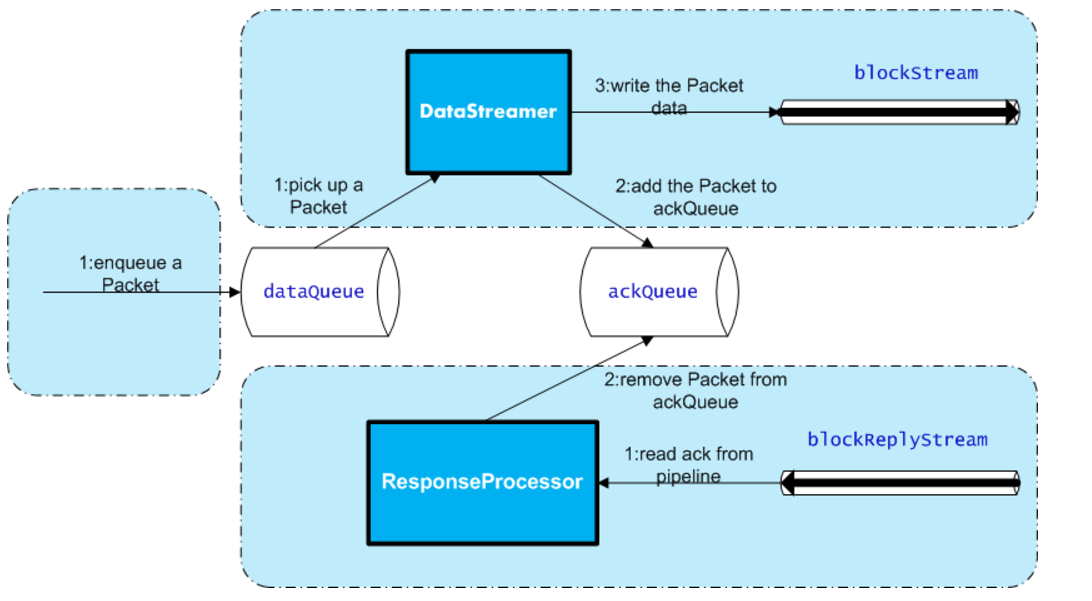
- DFSOutputStream将要写入的HDFS的文件分割成一些包,并将其写入到外置的data queue队列中.DataStrem消费这个队列,从namenode获取一些合适的datanode去存储这些包的副本.
- 假定副本级别为3,那么将有3个datanode在流水线中,DataStream线程将包发送给流水线中的第一个datanode存储完成后,依次转发给流水线后面的datanode进行此操作.
- 同时DFSOutputStream维护一个ack queue队列,等待流水线里所有datanode存储完成一个包之后,这个包从队列中移除.
假如有datanode写入失败,流水线将关闭,ack queue中的包将添加到data queue的前端以保证失败的节点下游的datanode不会丢失包.正常的节点会联系namenode,保证失败节点在恢复后删除掉这些包.余下的包将会写入正常节点,并会在另外的节点上复制,保证分片的数量.
DFSOutputStream内部原理示意图